Artifical Neural Network Analysis¶
Input data selection¶
When first running the ANN setup and training, A summary of glide identification features to be used are displayed

All experiments who have glide identification processing results that match those features will be listed for selection to be compiled into a dataset for the ANN.
You call select all experiments by typing all, or you can type the experiment’s ids individually in a list separated by commas.

After typing your selection and hitting enter, you will see the Theanets trainer initialize and begin the training process.
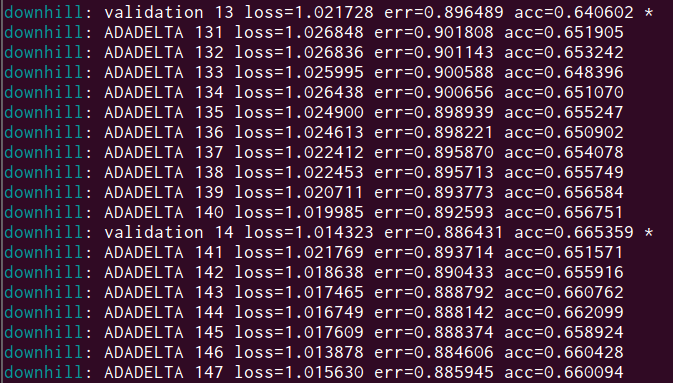
The training and validation data sets will automatically be split into min-batches by downhill, and you will see the training move onto the next mini-batch every so often.
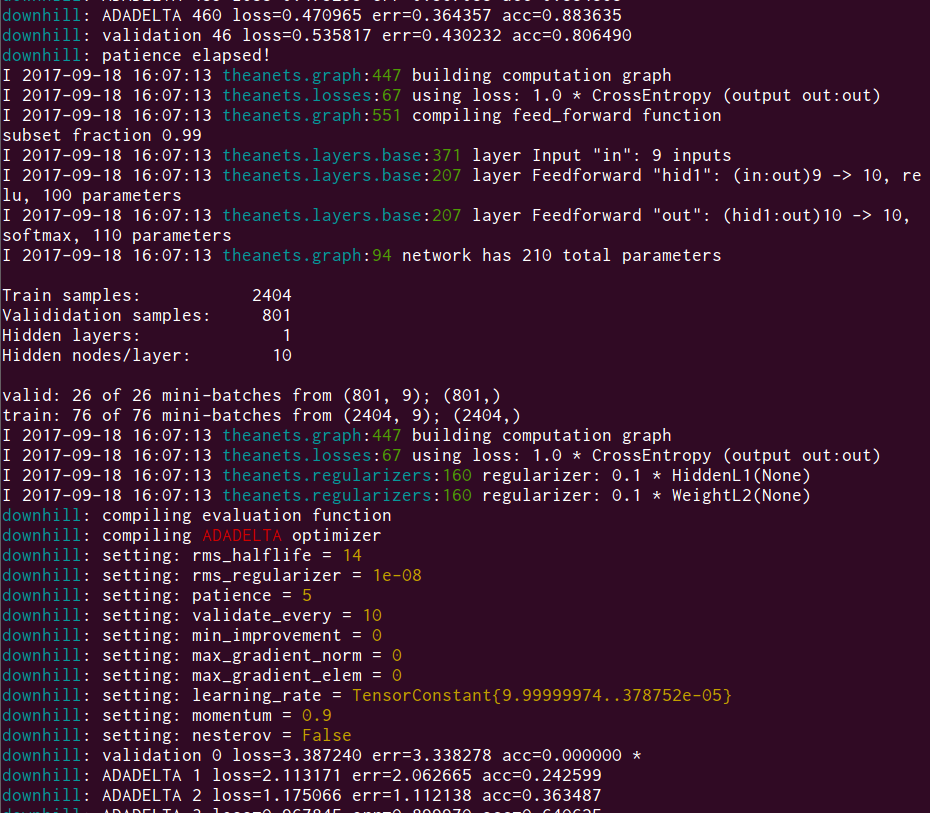
When the training is finished, the resulting accuracy of the tuning dataset size test will be displayed at the end of the console output.

Inspecting the results of the ANN¶
The Analaysis object will automatically be updated with the results of the current ANN run. You can see a summary of the results by looking at the post attribute:
# Typing this and hitting enter will show you summary of the ANN results
a.post
# To access data, concatenate the path to the data
import os
from smartmove.config import paths, fnames
path_output = os.path.join(a.path_project, paths['ann'], a.current_analysis)
# Get the tuning results
import pandas
filename_tune = os.path.join(path_output, fnames['ann']['tune'])
results_tune = pandas.read_pickle(filename_tune)
# Print all files and directories in the output directory
for f in os.listdir(path_output):
print('{}'.format(f))
Overview of ANN output¶
The following table gives an overview of all the files produced during the ANN tuning, dataset size test, and the post-processing. Note that the names for these files are set in smartmove.config.fnames and can be accessed in the ann field.
| Filename | File description |
| cfg_ann.yml | Copy of main ANN configuration for archiving with results |
| cms_data.p | Dictionary of confusion matrices for the dataset size test |
| cms_tune.p | Dictionary of confusion matrices for the tuning process |
| data_sgls.p | The compiled sub-glide data set with rho_mod added, from which datasets are split |
| data_sgls_norm.p | The compiled sub-glide data set with each column unit normalized |
| data_test.p | The test dataset tuple, where test[0] are the input features, and test[1] are the target values |
| data_train.p | The train dataset tuple, where train[0] are the input features, and train[1] are the target values |
| data_valid.p | The validation dataset tuple, where valid[0] are the input features, and train[1] are the target values |
| postprocessing.yml | The summary of the ANN results saved as YAML |
| results_dataset_size.p | The results of the dataset size test saved as a pandas.DataFrame |
| results_tuning.p | The results of the tuning process saved as a pandas.DataFrame |
| stats_input_features.p | Summary statistics calculated for the input features |
| stats_input_values.p | Summary statistics calculated for the target values |
YAML files can be easily read in any text editor, but you can also you yamlord to load them to a python dictionary:
import yamlord
# Manually open a post-processing YAML file
post = yamlord.read_yaml(os.path.join(path_output, 'postprocessing.yml'))
The files ending in .p are python pickle files, which you can use the pandas helper function to open:
import pandas
train = pandas.read_pickle(os.path.join(path_output, 'data_train.p'))